프로젝트 폴더 구조 및 개발환경 설정

위와 같은 구조로 폴더를 생성하였다.
data
⎹ processed: 전처리된 데이터(학습, 테스트 데이터) 저장
⎹ raw: 리뷰 데이터 원본 저장
notebooks
⎹ saved_models: 모델 개발 중간 과정들을 저장
⎹ ~.ipynb: 실제 코드

이후 venv를 통해 python 가상환경을 설정하여 각종 라이브러리의 버전 관리를 로컬과 분리하였다.
데이터 전처리
1. 데이터 타입 변환 및 결측치 확인

이후 진행할 time값 피처 엔지니어링을 위해 time 데이터의 타입을 object에서 datetime으로 변경하였다.
결측치 또한 없음을 확인하였다.
2. Time Feature Engineering

사용자의 특정 시점 패턴을 파악하기 위해 time 칼럼을 세분화하였다.
time 객체에서 아래의 4가지 파생 변수를 추출하였다.
- meal_time_code*
주문 시간을 'breakfast', 'lunch', 'dinner', 'late_night_snack'의 네가지 카테고리로 나누고,
이를 다시 정수형으로 인코딩하였다.
- day_of_week
요일을 0~6의 정수로 변환하였다.
- is_weekend
day_of_week 값을 기반으로 주말 여부를 0 또는 1로 나타내는 이진 feature를 생성하였다.
- is_holiday
holidays 라이브러리를 통해 한국의 공휴일 여부를 0 또는 1로 나타내는 이진 feature를 생성하였다.
* meal_time_code
단순히 아침밥은 0, 점심밥은 1, 저녁밥은 2, 야식은 3 으로 바꾸는 방식 즉, 레이블 인코딩은 의도치 않은 문제를 일으킬 수 있다.
모델이 숫자 사이의 크기관계(서열)까지 학습해버리기 때문이다.
예를 들어, 야식(3)을 아침(0)보다 크다고 학습할 수 있다.
따라서 one-hot 인코딩방식 또는 임베딩 레이어 방식을 사용해야 한다.
다만, 딥러닝 모델은 임베딩 레이어 방식을 사용하는 것이 좋다.
결론만 말하자면 더 적은 차원으로 데이터를 표현할 수 있고, 잠재적 패턴 학습을 기대해 볼 수 있다.
(추후 다세히 다뤄보는 글을 작성해 볼 예정)
따라서 각 카테고리를 고유한 정수로 매핑하는 전처리를 진행 한뒤, 추후 Two-Tower 모델의 임베딩 레이어에 입력값으로 사용한다.
리뷰 긍정 판별
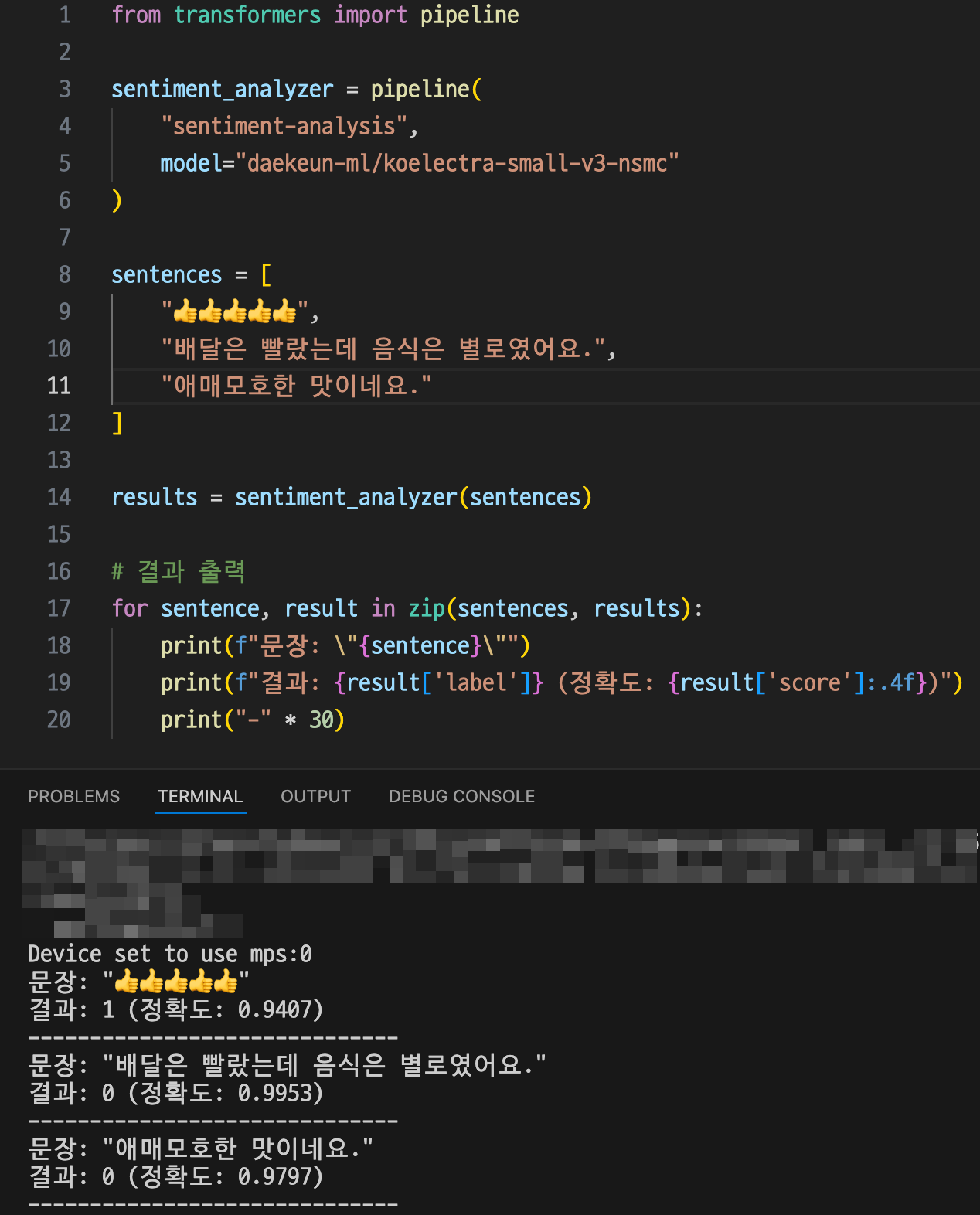
Hugging Face의 사전 학습된 감성 분석 모델 [ daekeun-ml/koelectra-small-v3-nsmc ]를 사용하였다.
Kc_Electra, Ko_Sbert 등 다양한 후보군이 있었으나, 상술한 모델이 직접 구성한 테스트 데이터에 대한 정확도가 가장 높았다.
또한, 본 프로젝트는 긍정/부정 여부 플래그만 있으면 되기 때문에 이 모델이 가장 적합하다는 판단에 채택하게 되었다.
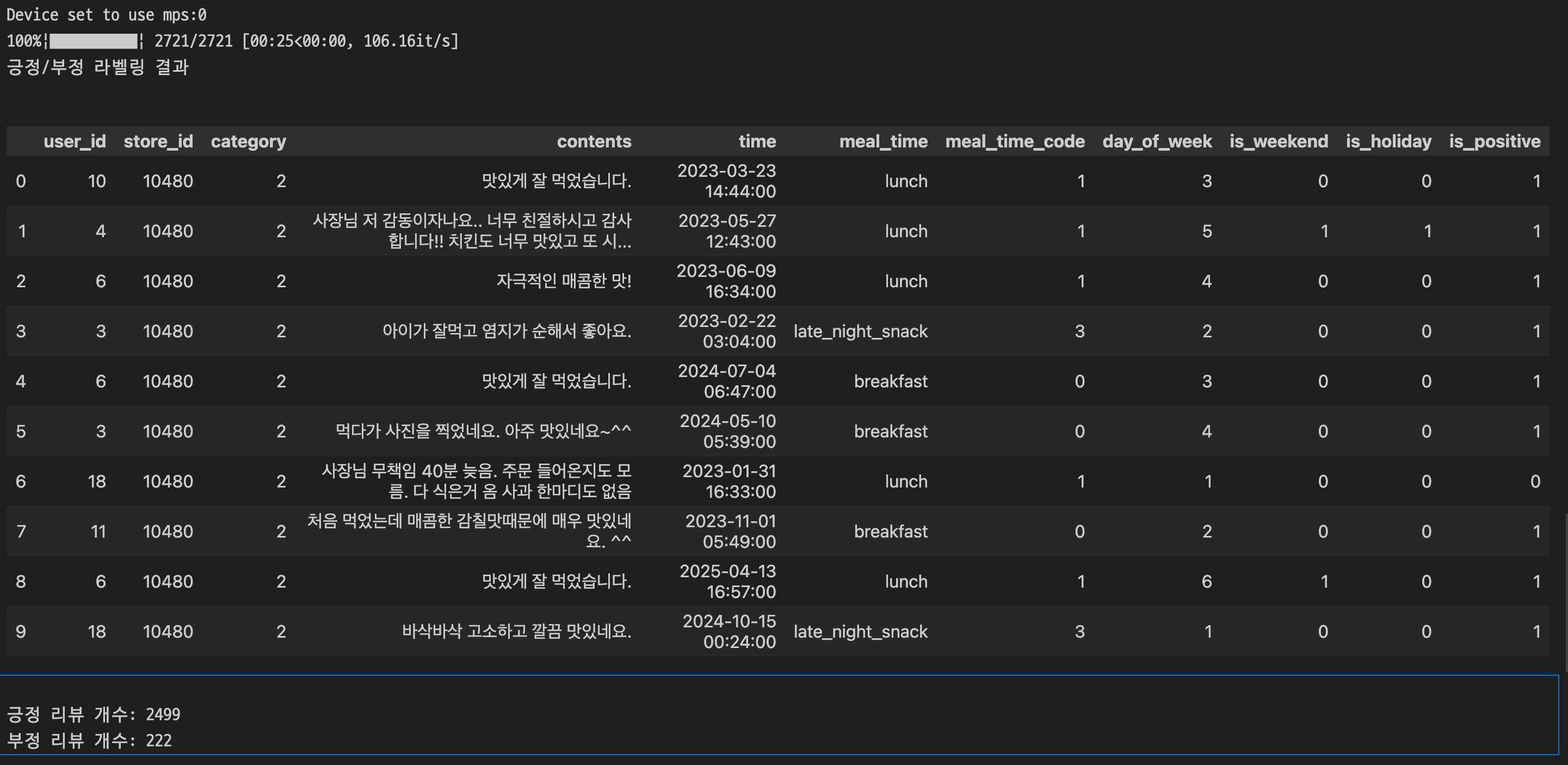
이후 모델을 메인 프로젝트로 가져와 contents 칼럼의 모든 리뷰 텍스트에 대해 감정 분석을 수행하였고, is_positive라는 새로운 칼럼에 저장하였다.
다만, 긍정 리뷰와 부정 리뷰의 개수가 심각한 불균형을 이루고 있다.
모델이 부정적 리뷰를 제대로 식별하지 못하는 문제가 발생할 수 있겠다는 생각이 들었다.
이 부분은 추후 모델 구현부에서 해결 방법을 찾아보도록 하겠다.
데이터 분할 및 저장

마지막으로 지금까지 전처리한 데이터를 Train data와 Test data를 8:2 비율로 분할하여 저장하였다.
현재 데이터가 수천개 정도로 많지 않은데다가 상기한 긍정/부정 불균형 문제도 있기 때문에, 추후 비율을 변경할 수도 있다.
개발 일정
0. 모델 선정 및 설계
1. 데이터 전처리
- 개발 환경 구축
- 세부 시간 feature 생성
- KcELECTRA(예정)를 이용한 선호 여부 라벨링
- 학습 데이터, 테스트 데이터 분할 및 저장
2. 모델 구조 설계 및 구현
- 데이터 파이프라인 구축
- User Tower, Item Tower 클래스 구현
3. 모델 학습 및 평가
- 모델 컴파일 및 학습
- 테스트 데이터셋을 이용한 성능 평가
4. 배포 준비 (Item Vector 사전 계산)
- 학습된 Item Tower를 이용해 모든 가게의 벡터 생성
- FAISS 인덱스 구축 및 저장
5. 실시간 추천 API 구현
- 서버 구성
- 모델 및 FAISS 인덱스 로드
- API 엔드포인트 생성
6. API 로직 완성 및 최종 테스트
- User Vector 생성 → FAISS 검색 → 결과 반환 로직 구현
- 통합 테스트
'Project > [AI] Deep Learning Model' 카테고리의 다른 글
| [추천 모델] 05. FAISS 인덱스, FastAPI 서버 구축 (0) | 2025.10.23 |
|---|---|
| [추천 모델] 04. 모델 구현 및 평가 (3): 모델 구현 마무리 (0) | 2025.10.17 |
| [추천 모델] 03. 모델 구현 및 평가 (2): Exp 2, 3 / Trouble Shooting (0) | 2025.10.16 |
| [추천 모델] 02. 모델 구현 및 평가 (1): Baseline Model (0) | 2025.10.16 |
| [추천 모델] 00. 모델 선정 및 설계 (0) | 2025.10.04 |



