Exp 2: category 추가

기존 Baseline 모델에 category feature를 추가했다.
분석

학습 데이터로 학습한 결과이다.
Loss Graph - 빨간 선
Baseline 모델과 같이 매우 안정적이다.
epoch 2에서 가장 낮은 손실값을 기록했으며, 이후로 미세하게 증가하며 overfitting의 조짐을 보였다.
Accuracy Graph - 빨간 선
첫 epoch부터 10%를 넘는 정확도를 보였으며, 최종적으로 14%까지 상승했다.
이를 통해 category feature를 통해 사용자의 취향을 더 잘 파악할 수 있게 되었다.
테스트 데이터를 통해 구한 Top-10 Accuracy는 약 15.6%이다.
Baseline 모델에 비해 7.1% 향상되었다. (14% 개선)
즉, 이 모델은 15.6% 확률로 상위 10개 목록에 실제 정답 가게가 포함된다.
이제 모델은 "한식을 좋아하는 사용자"와 "일식을 좋아하는 사용자"를 구분하고, 새로운 가게를 추천할 수 있는 일반화 능력이 생겼다.
Exp 3: meal_time_code 추가

이전의 Exp2 모델에 meal_time_code feature를 추가했다.
분석
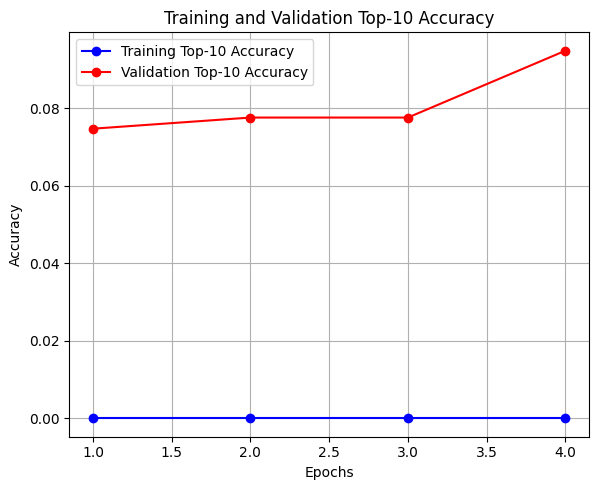
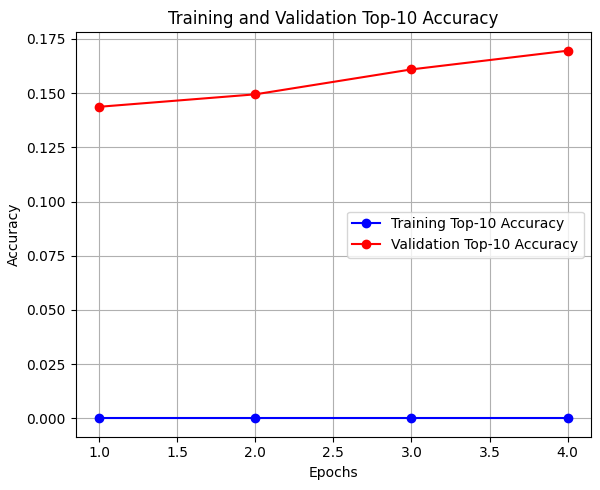


학습 데이터로 여러 번 학습한 결과이다.
학습을 시도할 때마다 정확도의 편차가 매우 크게 나타나는 문제가 발생했다.
동일한 코드임에도 불구하고 어떤 때는 성능이 오르고, 어떤 때는 오히려 떨어지는 등 결과를 신뢰하기 어려웠다.
문제 원인 분석
1. 작은 데이터셋 학습으로 인한 편차
현재로서는 해결 불가.
앞으로 더 많은 리뷰 데이터를 모아야 한다.
2. 현재 shuffle을 통해 데이터를 무작위로 섞고 있다.
어떨 때는 쉬운 문제가 많고, 어떨 때는 어려운 문제가 많다.
3. 초기 가중치를 아주 작은 무작위 값으로 초기화한다.
어떤 초기값은 좋은 결과로 빠르게 수렴하고, 어떤 초기값은 최저점에 수렴한다.
문제 해결

각 피처의 순수한 효과를 측정하기 위해, TensorFlow와 NumPy 등에서 사용하는 모든 난수의 시드값(seed)을 1로 고정하였다.
이를 통해 데이터셋 구성과 모델의 초기 가중치를 모든 경우에서 동일하게 통제했다.
이후 Baseline, Exp2와 Exp3의 학습을 처음부터 다시 진행하였다.
또한, 테스트 데이터를 이용한 테스트 결과도 같이 볼 수 있도록 코드를 수정하였다.
분석

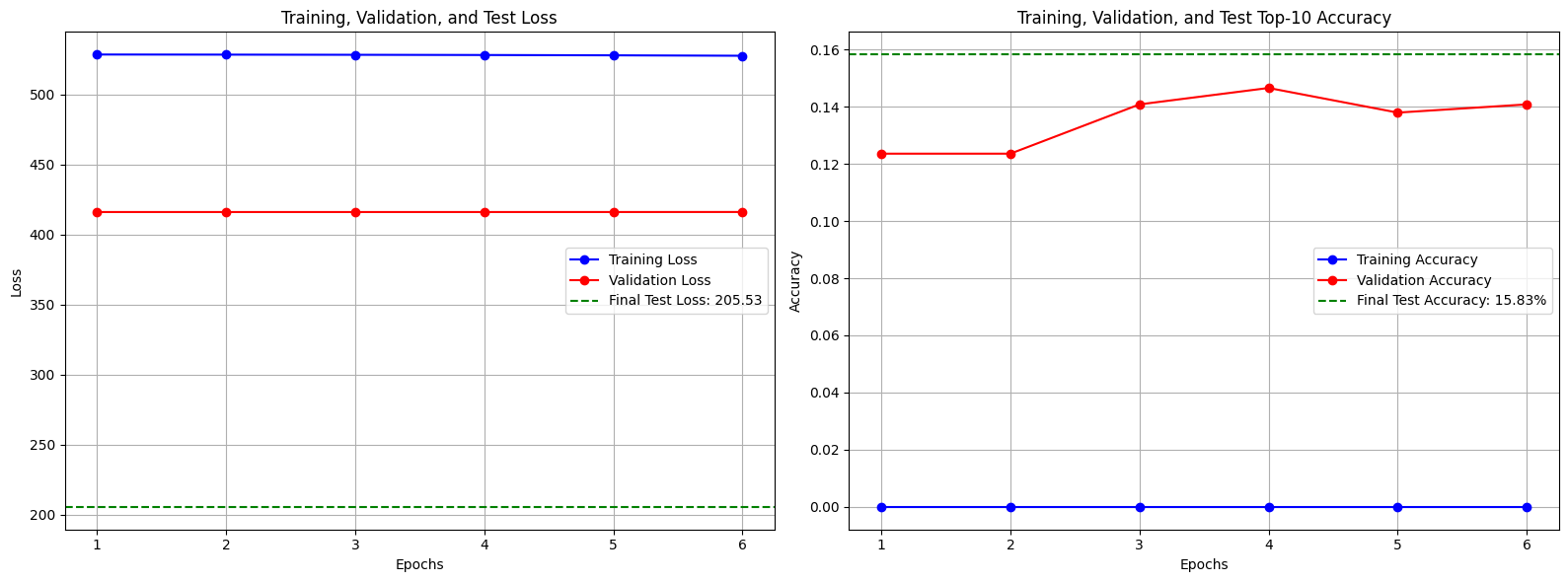
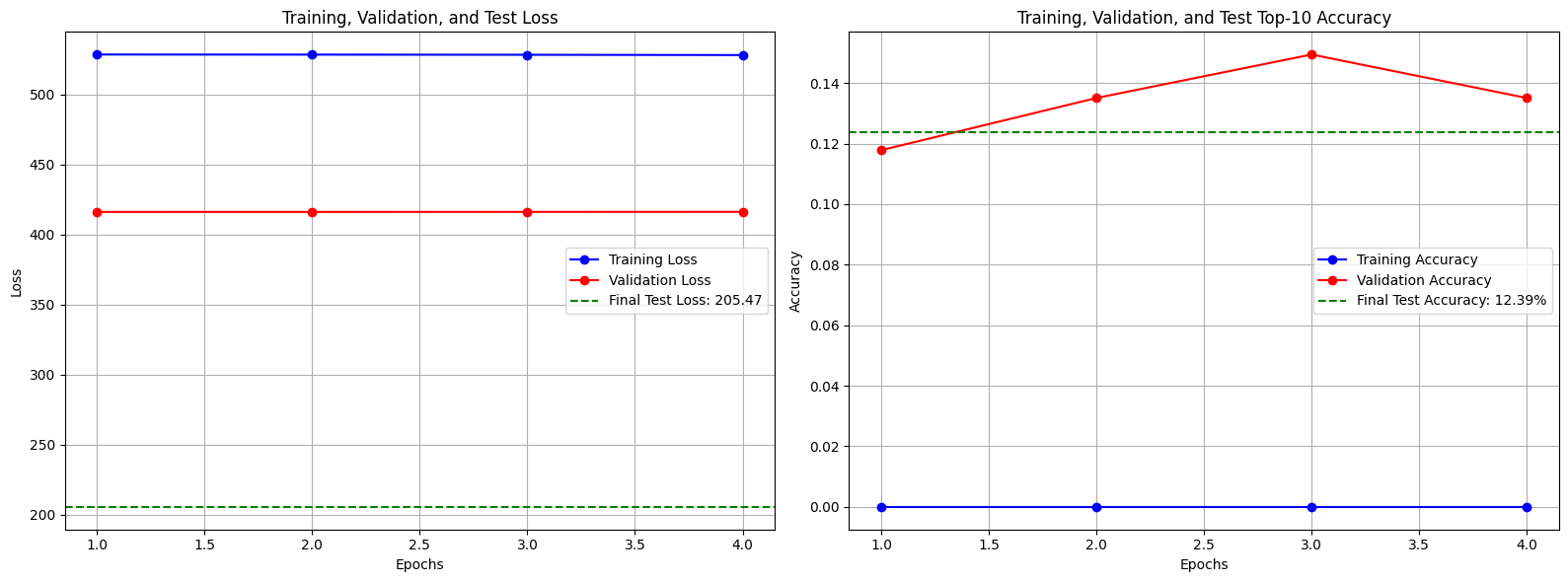
- Baseline: 13.76%
이전 글에 제시했던 최소한의 성능 기준선이 13.76%로 새롭게 설정되었다.
- Exp2: 15.83%
Baseline 모델에 비해 2.07% 성능 향상을 보였다.
이를 통해 category가 모델 성능에 중요한 영향을 미친다는 정보를 얻었다.
- Exp3: 12.39%
Baseline에 비해 1.37%, Exp2에 비해 3.44% 성능 하락을 보였다.
이를 통해 meal_time_code가 성능 향상이 아닌, 노이즈로 작용했을 가능성이 높다는 정보를 얻었다.
결론
1. 랜덤 시드값을 고정함으로써 랜덤하게 결정되는 요소를 통제하고, 각 피처가 모델 성능에 미치는 순수한 영향을 측정할 수 있는 환경을 구축했다.
2. category는 추천 성능을 유의미하게 향상시키는 핵심 피처임을 확인했다.
3. meal_time_code는 현재 데이터와 모델 구조에서는 성능에 기여하지 못하며, 오히려 노이즈로 작용할 수 있다.
개발 일정
0. 모델 선정 및 설계
1. 데이터 전처리
- 개발 환경 구축
- 세부 시간 feature 생성
- KcELECTRA(예정)를 이용한 선호 여부 라벨링
- 학습 데이터, 테스트 데이터 분할 및 저장
2. 모델 구조 설계 및 구현 (현재)
- 데이터 파이프라인 구축
- User Tower, Item Tower 클래스 구현
3. 모델 학습 및 평가 (현재)
- 모델 컴파일 및 학습
- 테스트 데이터셋을 이용한 성능 평가
4. 배포 준비 (Item Vector 사전 계산)
- 학습된 Item Tower를 이용해 모든 가게의 벡터 생성
- FAISS 인덱스 구축 및 저장
5. 실시간 추천 API 구현
- 서버 구성
- 모델 및 FAISS 인덱스 로드
- API 엔드포인트 생성
6. API 로직 완성 및 최종 테스트
- User Vector 생성 → FAISS 검색 → 결과 반환 로직 구현
- 통합 테스트
'Project > [AI] Deep Learning Model' 카테고리의 다른 글
| [추천 모델] 05. FAISS 인덱스, FastAPI 서버 구축 (0) | 2025.10.23 |
|---|---|
| [추천 모델] 04. 모델 구현 및 평가 (3): 모델 구현 마무리 (0) | 2025.10.17 |
| [추천 모델] 02. 모델 구현 및 평가 (1): Baseline Model (0) | 2025.10.16 |
| [추천 모델] 01. 데이터 전처리 (0) | 2025.10.14 |
| [추천 모델] 00. 모델 선정 및 설계 (0) | 2025.10.04 |



