FAISS의 정의, 선택 이유
FAISS란?
Facebook Ai Similarity Search의 약자로, Meta의 AI 연구소에서 개발한 유사 벡터 검색 라이브러리.
FAISS를 사용하는 이유
도서관에서 책 A와 비슷한 책 10권을 찾고자 하는 경우에 비유하자면,
일반적인 검색 방식은 모든 책을 책 A와 일일히 비교해야 한다.
만약 책이 수십, 수백만권이면 굉장히 오래 걸릴 것이다.
FAISS 방식으로 A와 비슷한 책 10권을 찾는 경우에는,
미리 도서관의 모든 책의 핵심 내용을 요약하여 색인을 만들어 둔다.
이후 색인을 활용해 A와 가장 비슷한 책 10권을 빠르게 찾아낸다.
현재 프로젝트에서 도서관의 책들은 가게 벡터(Item Vector)이고, 책 A는 사용자 벡터(User Vector)이다.
즉 FAISS는 추천 요청이 들어왔을 때, 사용자 벡터와 가장 유사한 가게 벡터들을 미리 저장해둔 수많은 후보 중에서 빠르게 찾아주는 역할을 한다.
구현

Step 1: 가게 벡터 로드
이전 단계에서 미리 학습하고 저장해 둔 모든 가게의 벡터 데이터(all_item_embeddings.npy)를 불러온다.
각 벡터는 각 가게의 특징을 담고 있다.
d = all_item_embeddings.shape[1]
벡터의 차원(이 모델에서는 32)을 확인하는 과정이다.

Step 2: FAISS 인덱스 생성
index = faiss.IndexFlatIP(d)를 통해 FAISS의 여러 인덱스 종류 중 IndexFlatIP라는 모델로 색인을 만든다.
Index
검색을 위한 색인 객체를 의미한다.
Flat
Brute Force 방식을 의미한다.
요청이 들어오면 인덱스 내의 모든 벡터와 일일이 비교하여 가장 정확한 결과를 찾는다.
데이터 양이 아주 많지 않을 때(수십만 개 이하)는 이 방식이 가장 정확하고 충분히 빠르다.
IP
내적(Inner Product)을 의미한다.
Two-Tower 모델은 User 벡터와 Item 벡터의 내적값이 클수록 '사용자의 취향과 가게가 잘 맞는다'고 판단한다.
따라서 유사도 기준으로 '내적'을 사용하는 IP 인덱스를 선택한 것이다.

Step 3: 인덱스에 벡터 추가
index.add(all_item_embeddings)
1단계에서 불러온 115개의 가게 벡터 모두를 2단계에서 만든 인덱스 공간에 추가한다.
이제 이 인덱스는 모든 가게의 특징 정보를 검색 가능한 형태를 갖추게 된다.

Step 4: 인덱스 파일로 저장
faiss.write_index(index, index_path)
완성된 인덱스를 faiss_index.bin이라는 하나의 파일로 저장한다.
저장해둠으로써, 나중에 API 서버를 실행할 때 이 파일만 불러오면 되므로 매번 인덱스를 새로 만드는 과정을 생략할 수 있다.
FastAPI 구축
최종 폴더 구조

원활하고 편리한 Fast API 서버 구동을 위해 개선한 최종 폴더구조이다.
main.py를 통해 서버를 실행하는 구조이다.
구현
Fast API 구현은 아래와 같다. (주석 참조)

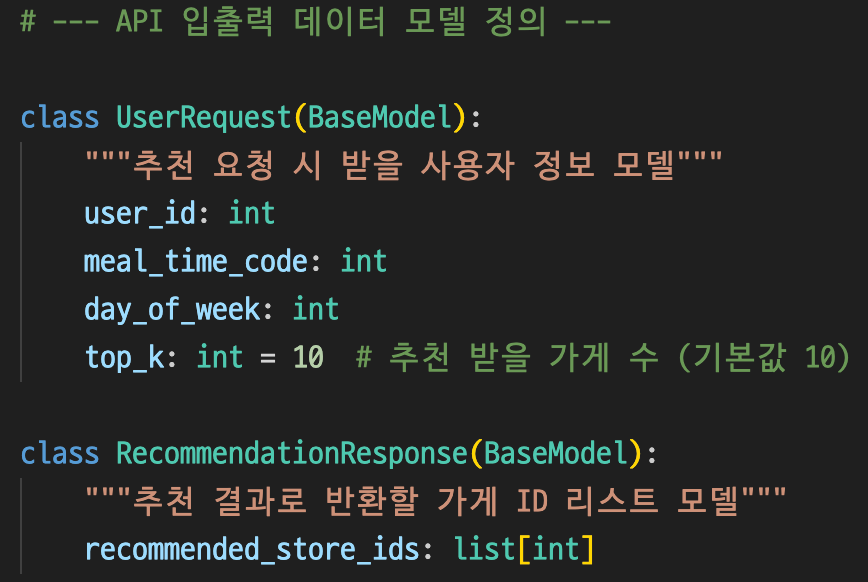

결론적으로,
user_id, meal_time_code, day_of_week을 파라미터로 받는 API 엔드포인트를 생성하게 된다.

uvicorn main:app
테스트

http://127.0.0.1:8000/docs 주소로 접속하게 되면 위와 같은 화면이 출력된다.
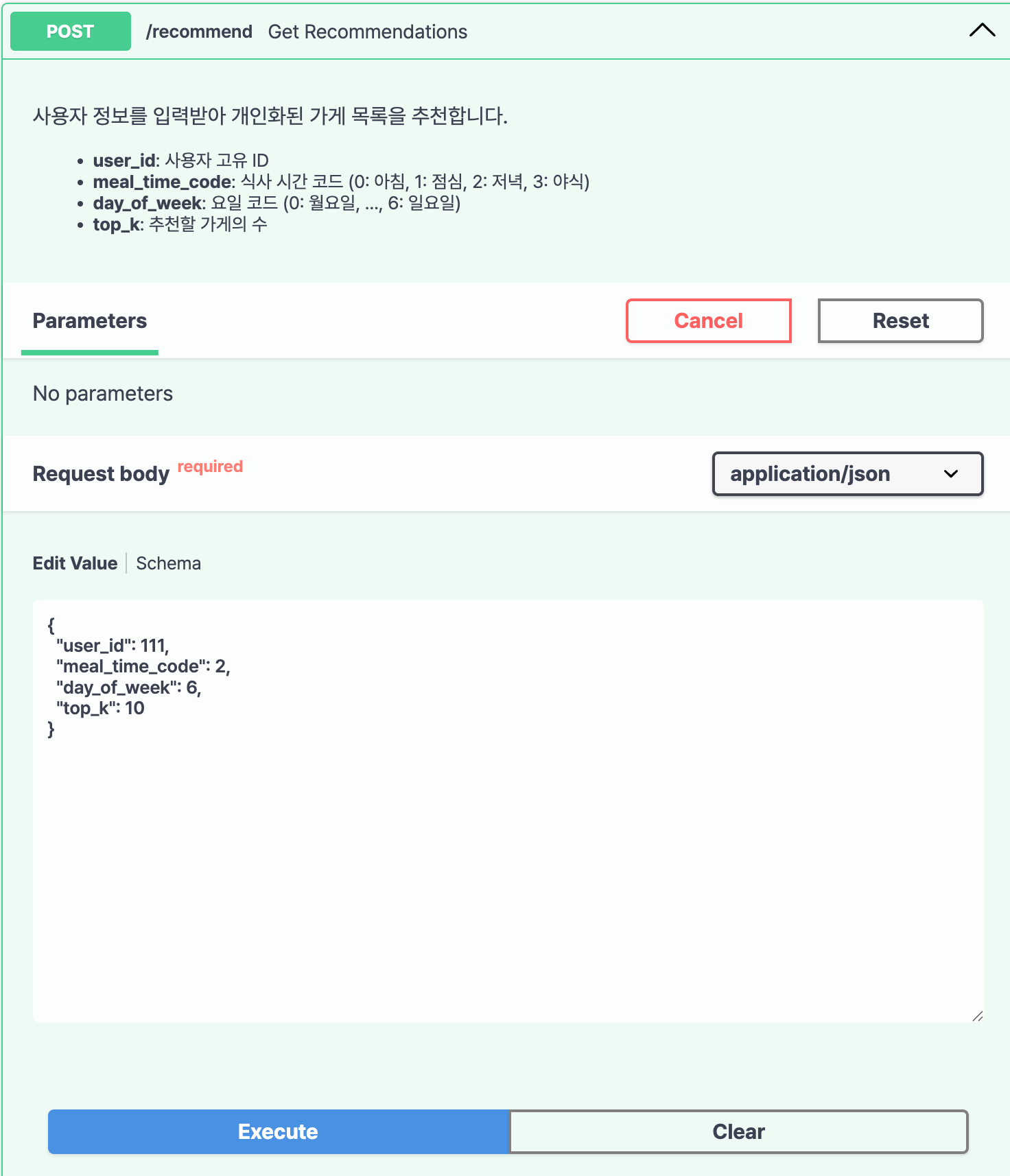
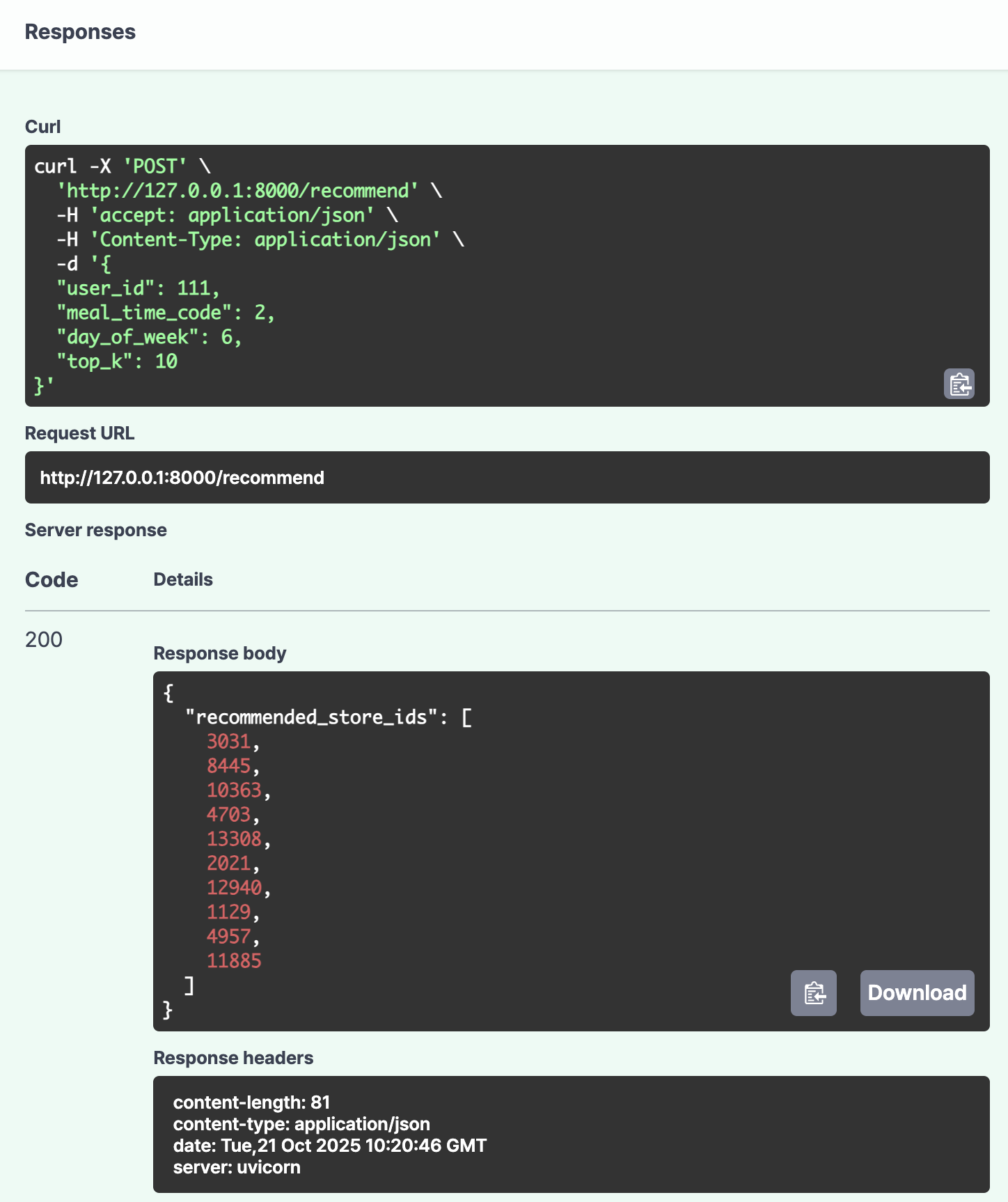
좌측 화면은 서버에 요청(POST)하는 화면이다.
user_id, meal_time_code, day_of_week, top_k 파라미터를 입력하면 그에 따라 API 서버에 요청을 하게 된다.
우측은 요청에 따른 응답 화면이다.
입력한 파라미터(사용자)와 유사한 store_id k개를 출력으로 내보낸다.
개발 계획
0. 모델 선정 및 설계
1. 데이터 전처리
- 개발 환경 구축
- 세부 시간 feature 생성
- KoELECTRA를 이용한 선호 여부 라벨링
- 학습 데이터, 테스트 데이터 분할 및 저장
2. 모델 구조 설계 및 구현
- 데이터 파이프라인 구축
- User Tower, Item Tower 클래스 구현
3. 모델 학습 및 평가
- 모델 컴파일 및 학습
- 테스트 데이터셋을 이용한 성능 평가
4. 배포 준비: FAISS 인덱스 구축 및 저장
- 학습된 Item Tower를 이용해 모든 가게의 벡터 생성
- FAISS 인덱스 구축 및 저장
5. API 구현
- FastAPI 서버 구성
- API 엔드포인트 생성
- 동작 테스트
6. NestJS 연동 및 E2E 테스트
- NestJS 백엔드에서 API 호출부 구현
- End to End 테스트
'Project > [AI] Deep Learning Model' 카테고리의 다른 글
| [추천 모델] 06. 백엔드 서버 연동 및 테스트 (完) (1) | 2025.11.01 |
|---|---|
| [추천 모델] 04. 모델 구현 및 평가 (3): 모델 구현 마무리 (0) | 2025.10.17 |
| [추천 모델] 03. 모델 구현 및 평가 (2): Exp 2, 3 / Trouble Shooting (0) | 2025.10.16 |
| [추천 모델] 02. 모델 구현 및 평가 (1): Baseline Model (0) | 2025.10.16 |
| [추천 모델] 01. 데이터 전처리 (0) | 2025.10.14 |



