Review Data 변경에 따른 재학습
기존 리뷰 데이터는 user_id가 약 20종류, review수가 2,000여개였다.
새로운 리뷰 데이터는 user_id가 약 370종류, review수가 3,700여개이다.
새로운 리뷰 데이터 바탕으로 지금까지의 모든 과정을 다시 진행해보겠다.

먼저, Baseline 모델이다.
테스트 정확도는 6.79%이다.
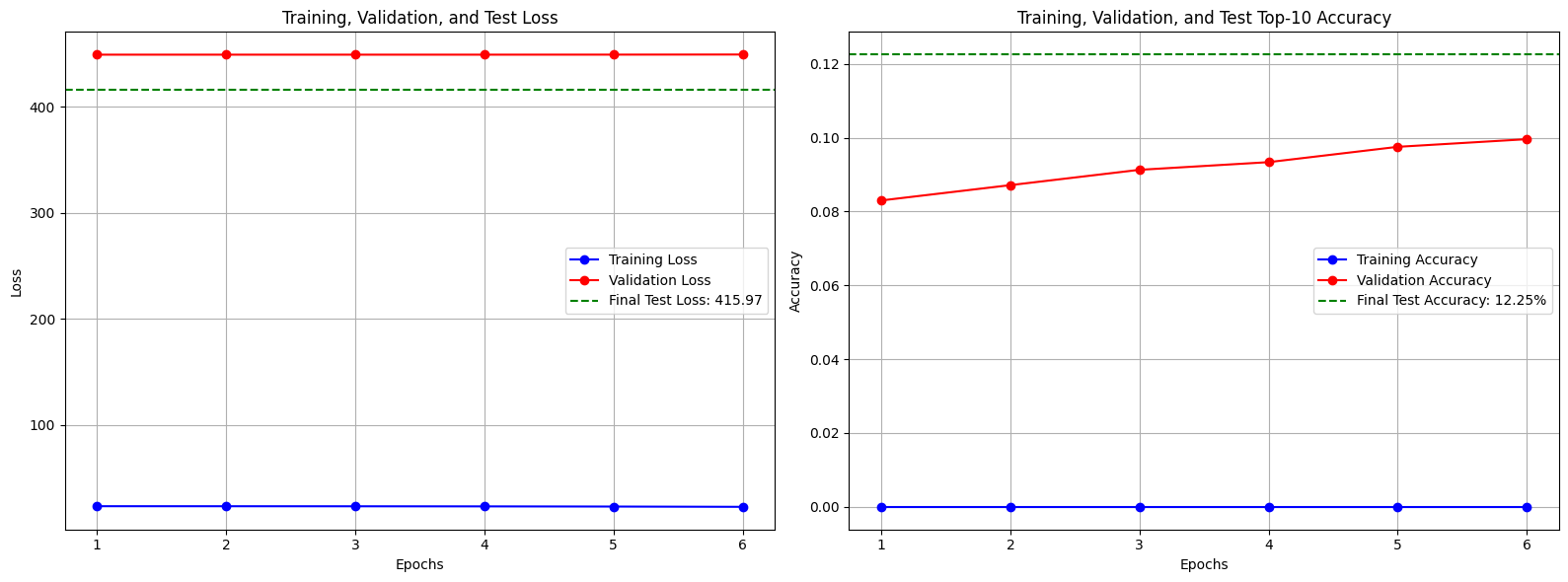
Exp2 모델이다.
테스트 정확도는 12.25%이다.
Baseline 모델에 비해 5.46%의 성능 향상을 보였다.

Exp3 모델이다.
이전 데이터셋을 통한 학습에서는 성능 감소 즉, 노이즈로 인식했었다.
테스트 정확도는 15.73%이다.
Exp2 모델에 비해 3.48%의 성능 향상을 보였다.
이전 데이터셋에서는 meal_time 피처가 사용자의 선호를 학습하기에 불충분하여 노이즈처럼 작용했지만,
데이터가 개선되면서 유의미한 패턴으로 학습한 것으로 예측된다.
Exp4: day_of_week 추가
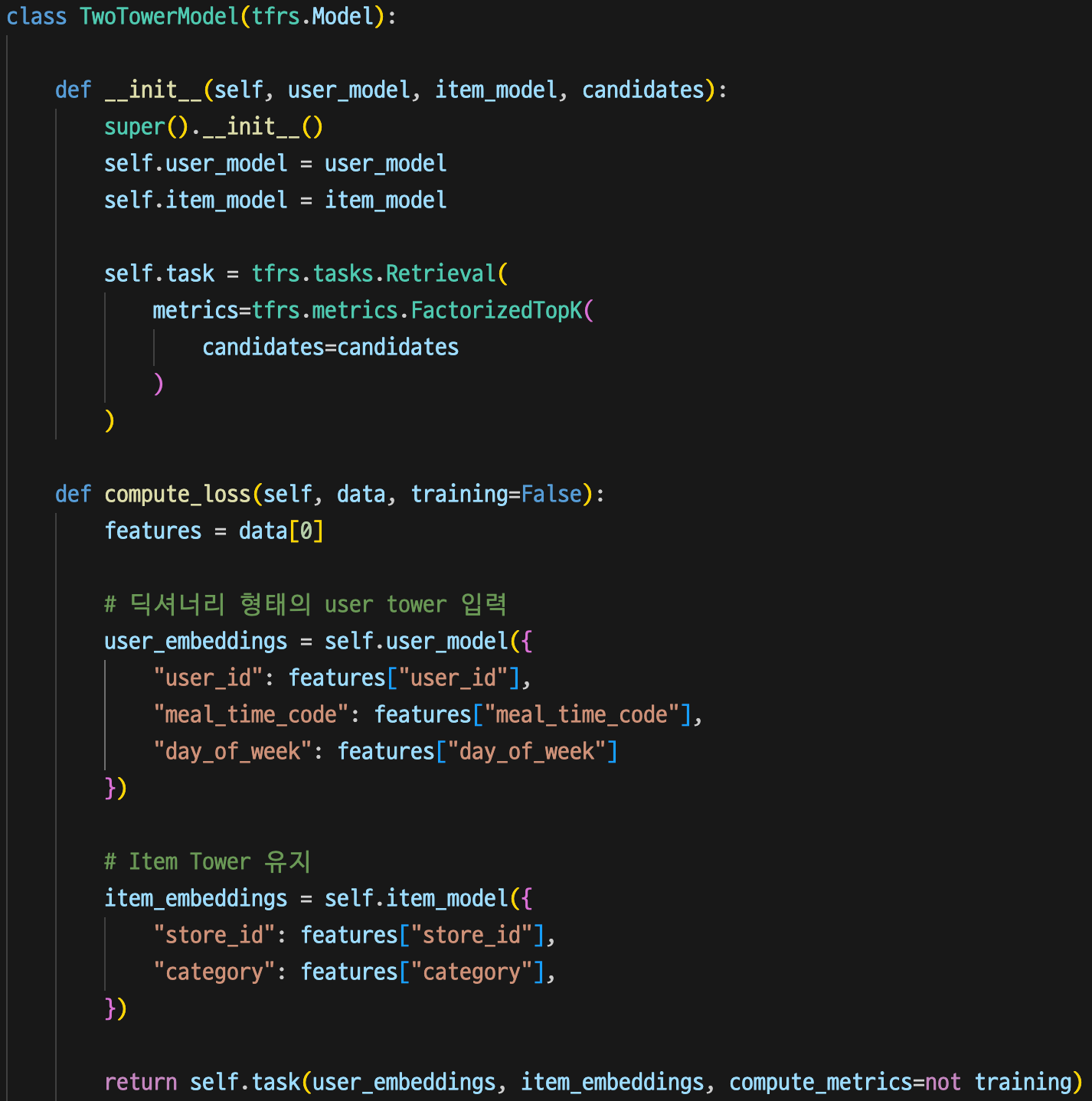
Exp3 모델에 day_of_week 피처를 추가하였다.
분석

테스트 정확도는 16.39%이다.
Exp3 모델에 비해 0.66%의 성능 향상을 보였다.
기존 모델에 day_of_week 피처가 결합하면서 "금요일 저녁", "월요일 점심", "일요일 아침" 등 훨씬 더 구체적인 문맥 정보가 생성되었다.
모델은 이제 "사용자가 평일 저녁에는 간단한 식사를 선호하지만, 주말 저녁에는 다같이 즐기는 식사를 선호한다"와 같은 복합적인 패턴을 학습할 수 있게 된것이다.
Exp 5-1: is_holiday 추가 (폐기)
비슷한 성격의 칼럼인 is_holiday와 is_weekend를 Exp5로 묶어 진행하였다.
사실 day_of_week 칼럼과 비슷한 성향의 칼럼들이지만, 혹시 모를 패턴이 발견될 수 있으므로 진행해본 것이다.
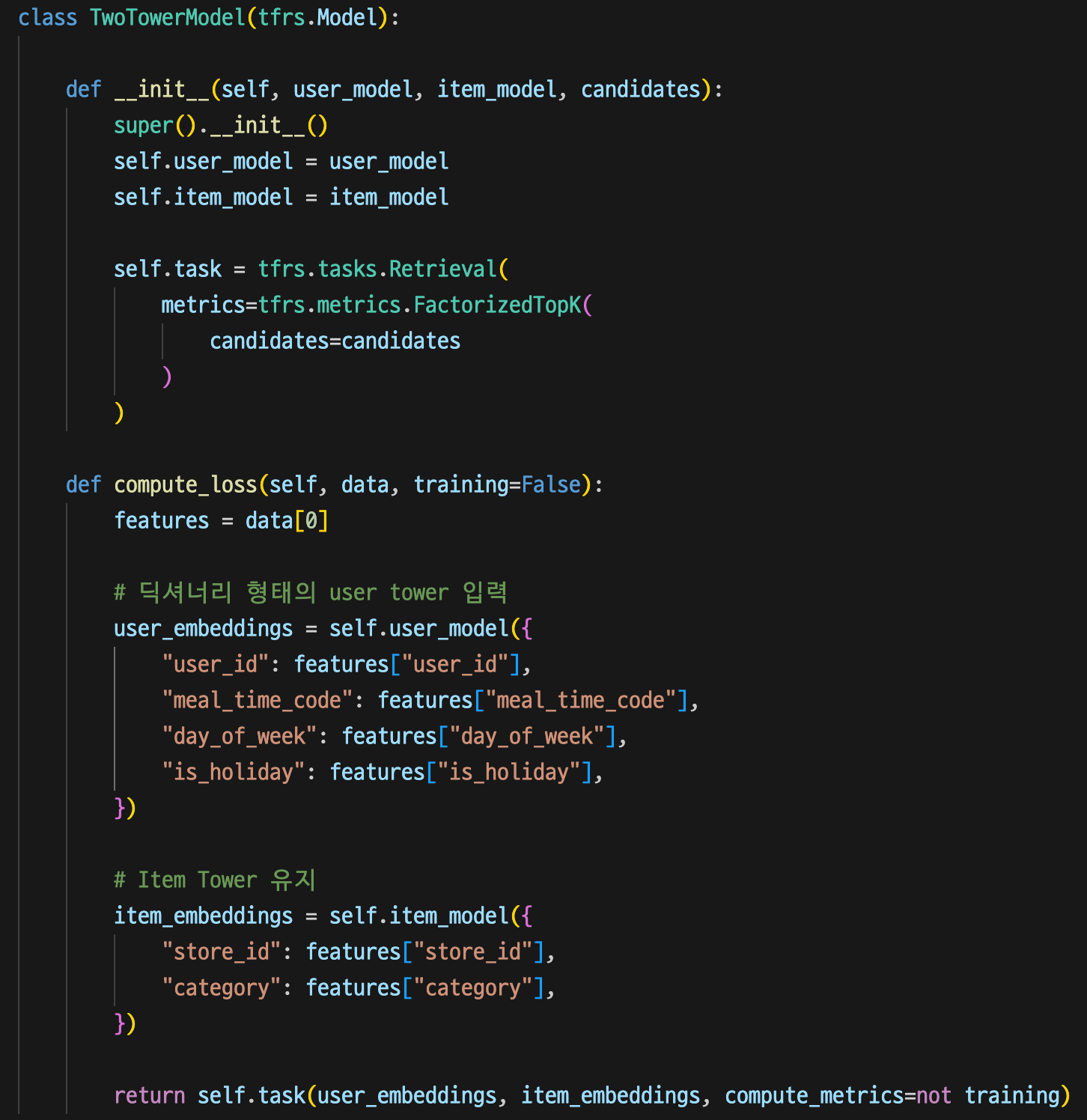
Exp4 모델에 is_holiday 피처를 추가하였다.
분석

테스트 정확도는 14.74%이다.
Exp3 모델에 비해 1.65%의 성능 하락을 보였다.
여전히 절대적인 데이터 수가 부족하여 1년에 10~15일정도밖에 되지 않는 is_holiday 데이터가 오히려 노이즈로 작용한것이다.
피처는 추가되며 모델의 복잡도는 증가하였지만, 그에 상응하는 유용한 정보를 제공받지 못한 것이기 때문에 오히려 학습 난이도가 상승하여 성능이 하락한 것으로 예측된다.
Exp 5-2: is_weekend 추가 (폐기)

Exp4 모델에 is_weekend 피처를 추가하였다.
분석
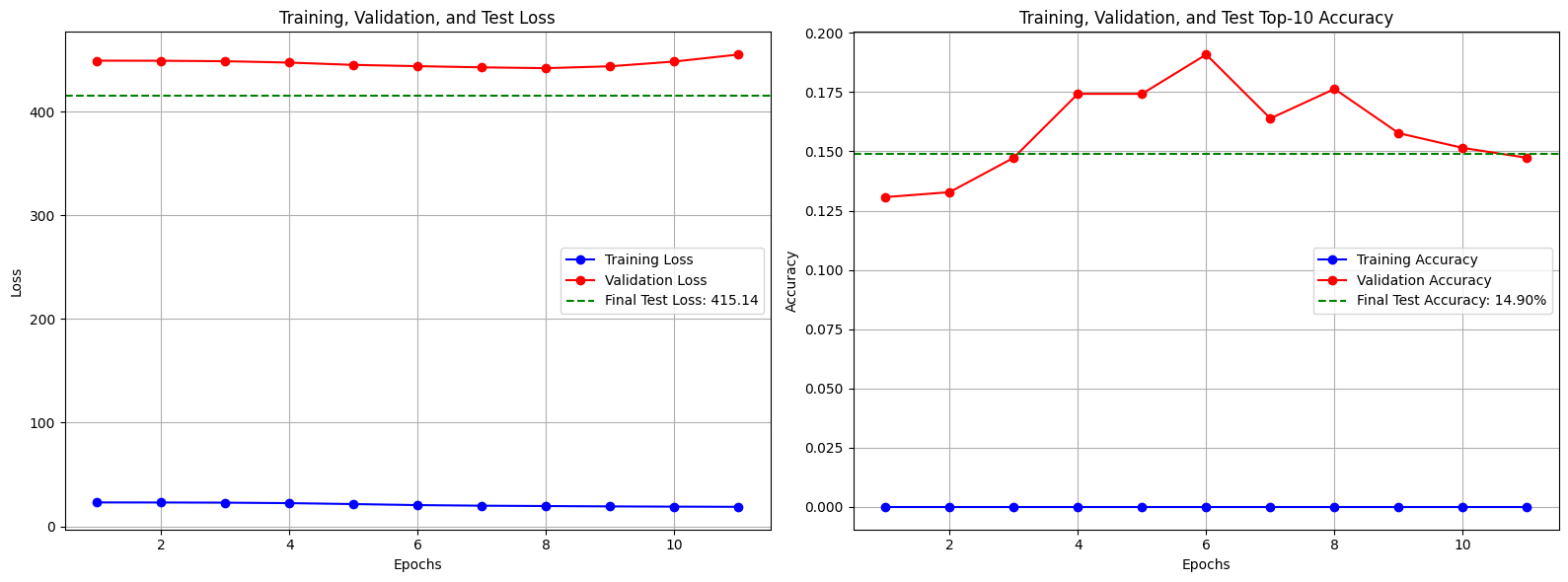
테스트 정확도는 14.90%이다.
예상대로 Exp3 모델에 비해 1.49%의 성능 하락을 보였다.
is_weekend는 day_of_week칼럼을 요약한 정보라고 볼 수 있다.
즉 이 칼럼은 완전히 종속적인 정보이기 때문에 새로운 정보를 제공하지 못한다.
예를 들면, 한반도 지도(day_of_week)와 서울 지도(is_weekend) 두 개를 주고 길을 찾으라고 하는 것이다.
서울 지도는 한국 지도에 이미 포함된 정보를 가지고 있으므로, 길찾기에 도움을 주지 못하고 오히려 혼란을 줄 수 있다.
모델 학습 마무리
리뷰를 고정된 차원의 벡터로 변환하여 item tower에 추가하는 방식 등 아직 모델 개선의 여지가 남아있다.
하지만 모델 개선은 Exp 4에서 중단 후 나중에 진행하고, 배포 준비 단계를 진행해 보도록 하겠다.
개발 계획
0. 모델 선정 및 설계
1. 데이터 전처리
- 개발 환경 구축
- 세부 시간 feature 생성
- KoELECTRA를 이용한 선호 여부 라벨링
- 학습 데이터, 테스트 데이터 분할 및 저장
2. 모델 구조 설계 및 구현
- 데이터 파이프라인 구축
- User Tower, Item Tower 클래스 구현
3. 모델 학습 및 평가
- 모델 컴파일 및 학습
- 테스트 데이터셋을 이용한 성능 평가
4. 배포 준비: FAISS 인덱스 구축 및 저장
- 학습된 Item Tower를 이용해 모든 가게의 벡터 생성
- FAISS 인덱스 구축 및 저장
5. 실시간 추천 API 구현
- 서버 구성
- 모델 및 FAISS 인덱스 로드
- API 엔드포인트 생성
6. API 로직 완성 및 최종 테스트
- User Vector 생성 → FAISS 검색 → 결과 반환 로직 구현
- 통합 테스트
'Project > [AI] Deep Learning Model' 카테고리의 다른 글
| [추천 모델] 06. 백엔드 서버 연동 및 테스트 (完) (1) | 2025.11.01 |
|---|---|
| [추천 모델] 05. FAISS 인덱스, FastAPI 서버 구축 (0) | 2025.10.23 |
| [추천 모델] 03. 모델 구현 및 평가 (2): Exp 2, 3 / Trouble Shooting (0) | 2025.10.16 |
| [추천 모델] 02. 모델 구현 및 평가 (1): Baseline Model (0) | 2025.10.16 |
| [추천 모델] 01. 데이터 전처리 (0) | 2025.10.14 |



